

1. 分类误差与泛化误差(Classification Error & Generalization Error)
A. 分类误差的三种类型
B. 分类对比
\text{Generalization Error} \approx \text{Expected Test Error} > \text{Training Error}
-
当模型简单时,三者接近。
-
当模型复杂时,训练误差趋近 0,但测试误差反而上升(过拟合)。
-
错误率 (error rate) = 错误分类数 / 总样本数
-
准确率 (accuracy) = 1 − 错误率
C. 训练误差 \leq 泛化误差
训练误差(training error)永远低估模型的真实错误率(泛化误差)。
-
模型是为了拟合训练数据而“优化”的
-
决策树、神经网络、SVM……都在“训练集”上反复调整参数。模型自然会在训练样本上表现越来越好。
-
但这些调整可能过度匹配噪声 → 在新数据上失败。
-
-
训练误差缺乏独立性
-
训练集和模型之间存在信息泄露(data reuse):模型“见过这些样本”。
-
因此训练误差反映的是“拟合效果”,而不是“预测能力”。
-
2. 欠拟合与过拟合(Underfitting vs Overfitting)
A. 两者对比
本质的问题是,你得考虑泛化。你通过模拟考试弄出来的东西,真正考试的时候不一定这么出。你把模拟考试的答案背下来直接去写真实考试,这就是过拟合。但是你模拟考试都没弄明白,那就是欠拟合。泛化能力才是关键。
B. 误差曲线
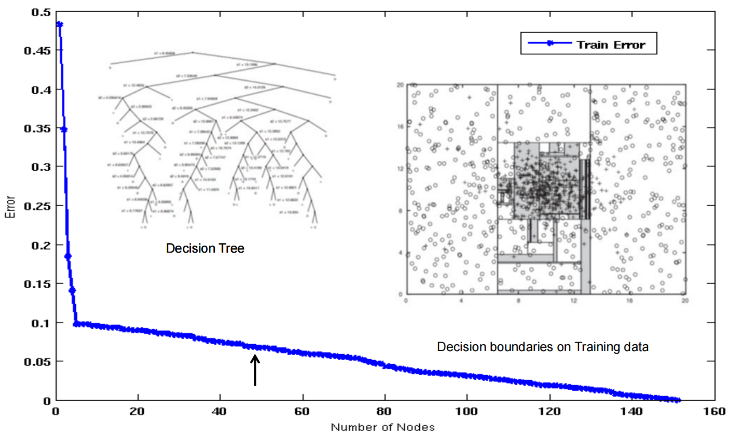
你可以看出来,模型的复杂度对拟合的帮助在一个临界值之后快速下降。
误差曲线形状
即 U 形关系:
-
起初增加复杂度有助于减少误差。
-
超过最佳点后,模型开始学习“噪声”。
C. 过拟合的原因
a. 数据不足 (Insufficient Training Data)
-
核心结论 训练数据量越大,过拟合风险越低。
-
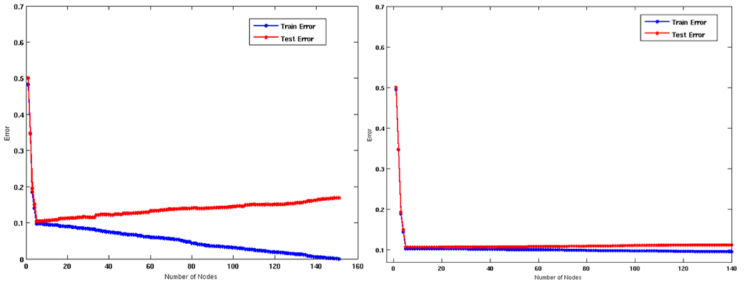
-
第二张图是两倍数据量的结果。
b. 模型太复杂 (Excessive Model Complexity)
其实就是所谓的读书读太杂了,然后又不能整合,看到核心问题。
决策树节点过多、神经网络层太深、参数过多都会导致:
-
高方差 (variance);
-
模型过度响应训练集的特定结构。
-
复杂模型拥有更高的“容量 (capacity)”:能拟合更多模式,包括错误模式。
c. 多重比较问题 (Multiple Comparison Procedure)
“在足够多次尝试下,总能找到一个看似完美但其实随机的结果。”
—— 不知道是谁
-
举例:如果我们测试100个属性,即使所有属性与类别完全无关,也可能偶然出现一个属性“看起来”能完美划分训练样本。
-
这是随机波动被误认为规律的典型情况。类似反复试错直到“碰巧”猜对一次。
想象有 50 个股票分析师:
-
每人随机预测市场涨或跌。
-
第一周后,大约 25 人预测对。
-
第二周,这 25 人再随机预测,又有约 12–13 人连对两次。
-
到第 6 周,可能有一个分析师“连续6次预测对”。→ 看起来他“超神”,但实际上是随机概率的产物。
D. 解决方法
验证集,一般就是82分,百分之八十用来训练,百分之二十用来验证。
那么怕这个验证多了出现问题,所以一般我们随机切割这个东西,比如随机分十个八二分,我们就有了交叉验证。
显著性矫正就是,对于交叉验证来说,每次的错误不能累加,比如十次交叉验证之后,你这个错误率也得处以10来平衡。
3. 模型选择与复杂度惩罚(Model Selection & Complexity Penalty)
模型越复杂,训练误差越低, 但是过拟合的风险就越高;但为了防止过拟合,我们要在误差与复杂度之间权衡。
A. 方法一:使用验证集评估模型
-
将训练集拆成:子训练集(用于拟合参数);验证集(用于比较不同模型的性能)。选出在验证集上错误率最小的模型。
这种做法本质上用经验泛化误差来评估不同模型复杂度的好坏。
B. 方法二:在目标函数中加入复杂度惩罚
复杂度惩罚项可以取决于:
-
模型的自由参数数量(参数越多,惩罚越大);
-
树的深度、节点数等结构指标;
-
模型的不确定性或容量(capacity)。
C. 悲观误差估计
Structural Risk Minimization (SRM) 对应着 奥卡姆剃刀法则 :“如无必要,勿增实体。”
在能实现相同效果的时候,优先选择更简洁的模型。
那么对应到选择树上,我们考虑的是,如果减去某项分类,到底会不会优化?
a. 案例
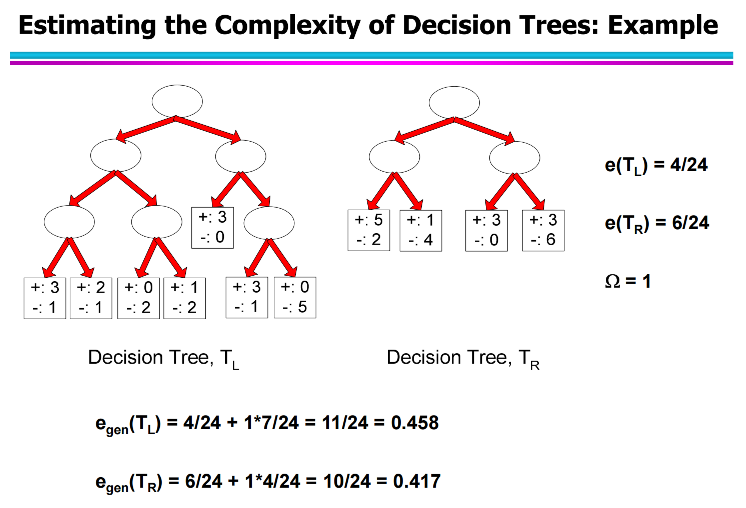
比较两棵树:
-
Tₗ(左树):更复杂(更多叶子)
-
Tᵣ(右树):更简单(更少叶子)
两者训练样本总数都是 N_{train}=24,惩罚系数设为 \Omega = 1。
b.计算训练误差 err(T)
看右边标注:
这个是每个方框内较小的数字的相加。
-
e(T_L) = 4/24 = 0.167
-
e(T_R) = 6/24 = 0.25
也就是说:
• 左树更复杂,训练误差更低;
• 右树更简单,训练误差略高
c. 确定叶子数 k
观察图示:
• 左树 T_L:最底下红框共 7 个叶子
• 右树 T_R:只有 4 个叶子
所以:
k_L = 7, \quad k_R = 4
d.代入“悲观误差”公式
其中 \Omega = 1,\; N_{train}=24。
左树 T_L
右树 T_R
e. 结果解读
D. C4.5 的方法
类似的道理,但是换一些参数罢了。
-
e = 节点中的错误样本数;
-
n = 节点样本总数;
-
CF = 置信因子(C4.5 默认 0.25,对应 z = 0.69)。
4. 模型优化之”减树枝“
A. Pre-Pruning(预剪枝 / Early Stopping Rule)
在建树过程中提前停止扩展节点,防止树长得太深。也叫 “早停法”。它在模型构建阶段就决定“不再往下分”。
a. 典型停止条件
1. 所有样本属于同一类→ 节点已经纯净,无需继续分裂。
2. 所有属性取值完全相同→ 再分也不会带来信息增益。
b. 更严格的停止条件(Practical Rules)
B. Post-Pruning(后剪枝 / Subtree Replacement)
先把树完整地长出来,再从底部往上逐步“修剪”不必要的分支。又称 Subtree Replacement(子树替换)。
操作步骤
1. 先构建完整树(即使可能过拟合)。
2. 自底向上检查每个节点的子树:临时将该子树剪掉,用一个叶子节点替代。
3. 计算剪前剪后泛化误差(或验证误差):
-
如果剪枝后误差不变或下降 → 确认剪枝。
-
否则恢复原子树。
4. 新叶节点的类别标签由该子树中样本的多数类决定。
C. 对比总结
总结
-
预剪枝:贪心、快速、风险是“停早”;
-
后剪枝:先放手学,再审慎减,泛化更强;
-
实际上现代树模型(如 Random Forest, GBDT)都默认包含某种后剪枝或正则化机制。
4. 最小描述长度原则(Minimum Description Length, MDL)
A. 总编码长度最短
最优模型 = 能最简洁地解释数据的模型。也就是说,我们希望选择那个总编码长度最短的模型
其中:
-
L(\text{Model}):编码模型本身需要的“长度”(越复杂的模型越长);
-
L(\text{Data | Model}):在给定模型下,描述剩余误差(data residuals)所需的“长度”。
目标是让两者之和最小。
如果模型太简单 → L(\text{Model}) 很短,但 L(\text{Data | Model}) 很长(模型解释不了数据,残差多)。
• 如果模型太复杂 → L(\text{Model}) 很长(要描述太多参数、分支),即使残差短也不划算。
• MDL 找的是两者平衡点。
👉 这和我们之前的:
\text{Generalization Error} = \text{Training Error} + \text{Complexity Penalty}
完全一致,只是换了“信息论”语言。
B.在决策树中的应用
L(\text{Model}):
-
描述整棵树的结构(每个节点用哪个属性、阈值、分支数)。
-
L(\text{Data | Model}):对叶节点中的错误样本编码(多少条样本被错分)。
剪枝策略:
-
若剪掉某个子树能使 L_{\text{total}} 变短 → 就剪。
-
否则保留。
C. 例子
还是用上面的例子

左树 T_L:节点结构与数据分布
右树 T_R:节点结构与数据分布
应用 MDL 原理对比, 我们假设:
-
每个叶子的结构编码成本 c 比特;
-
每个误分样本的代价 b 比特。
-
MDL 的总编码长度:我们设置了不同的c 和 b 来对比想要的效果。
5. 模型评估方法(Model Evaluation and Model Selection)
这个在上一章我们就稍微说了一下,但是我们这一次复习加上添加一些新的东西。
建立分类模型后,我们要回答两个核心问题:
1. 模型泛化得好吗?→ 评估它在未见数据上的表现。
2. 哪个模型最好?→ 对比不同参数/算法/复杂度下的泛化性能。
A. 留出法(Holdout Method)
将数据随机划分为两部分:
-
Training set(训练集)——用于拟合模型。
-
Test set(测试集)——用于估计泛化误差。
常用比例:
-
70% 训练 / 30% 测试
-
80% 训练 / 20% 测试
问题
-
结果依赖于随机划分;
-
如果样本较少,测试集太小 → 估计方差大;
-
如果测试集太大 → 训练数据不够。
B. 交叉验证法(Cross-Validation)
a. k-Fold Cross-Validation
1. 将数据随机划分为 k 个等大小子集。
2. 每次取其中 1 份作验证集,其余 k-1 份作训练集。
3. 重复 k 次,每次验证集不同。
4. 最终性能 = 平均验证误差。
常用取值:k=5 或 k=10。
优点
-
利用全部数据进行训练与验证;
-
减少划分偶然性;
-
更适合小样本场景。毕竟你要跑5-10遍。
b. k-fold的变形
C. 自助法(Bootstrap Method)
从原始数据集中有放回地随机抽样 n 次(与样本总数相同)。
-
约 63.2% 的样本被抽到(训练集);剩下约 36.8% 的样本作为“袋外样本 (out-of-bag)”用于测试。
-
对多次自助样本计算误差,再取平均。
相当于你在复制里面的数据嘛。然后相当于放大了里面的微小趋势。
D. 嵌套交叉验证(Nested Cross-Validation)
当我们需要模型选择 + 性能评估同时进行时(例如调超参数)。
外层交叉验证:用来评估模型最终泛化性能。
内层交叉验证:用来在不同超参数或模型之间进行选择。
-
外层划分成 K 折。
-
在每一折中,用内层交叉验证挑选最佳模型/参数;再在外层验证集上计算泛化误差。
-
最终外层平均误差 = 模型的可靠估计。